标题 :
中外大模型数学能力大比拼
内容 :
遇到一个数学问题,懒得推导了。习惯性让GPT推一下。
最开始问题给错了,然后纠正了一下,貌似GPT就鬼打墙出不来了。给的答案也不对。

可能受上下文影响。那重开一个对话,结果还是不对。要么说没有解

要么继续胡说八道。

抱着试试看的态度,把同样的问题扔给了豆包和deepseek。
deepseek速度快,结果也对,但是过程是不对的。

豆包过程比较绕,但是基本正确,结果也是对的。

当然,都不如人推导的哈。
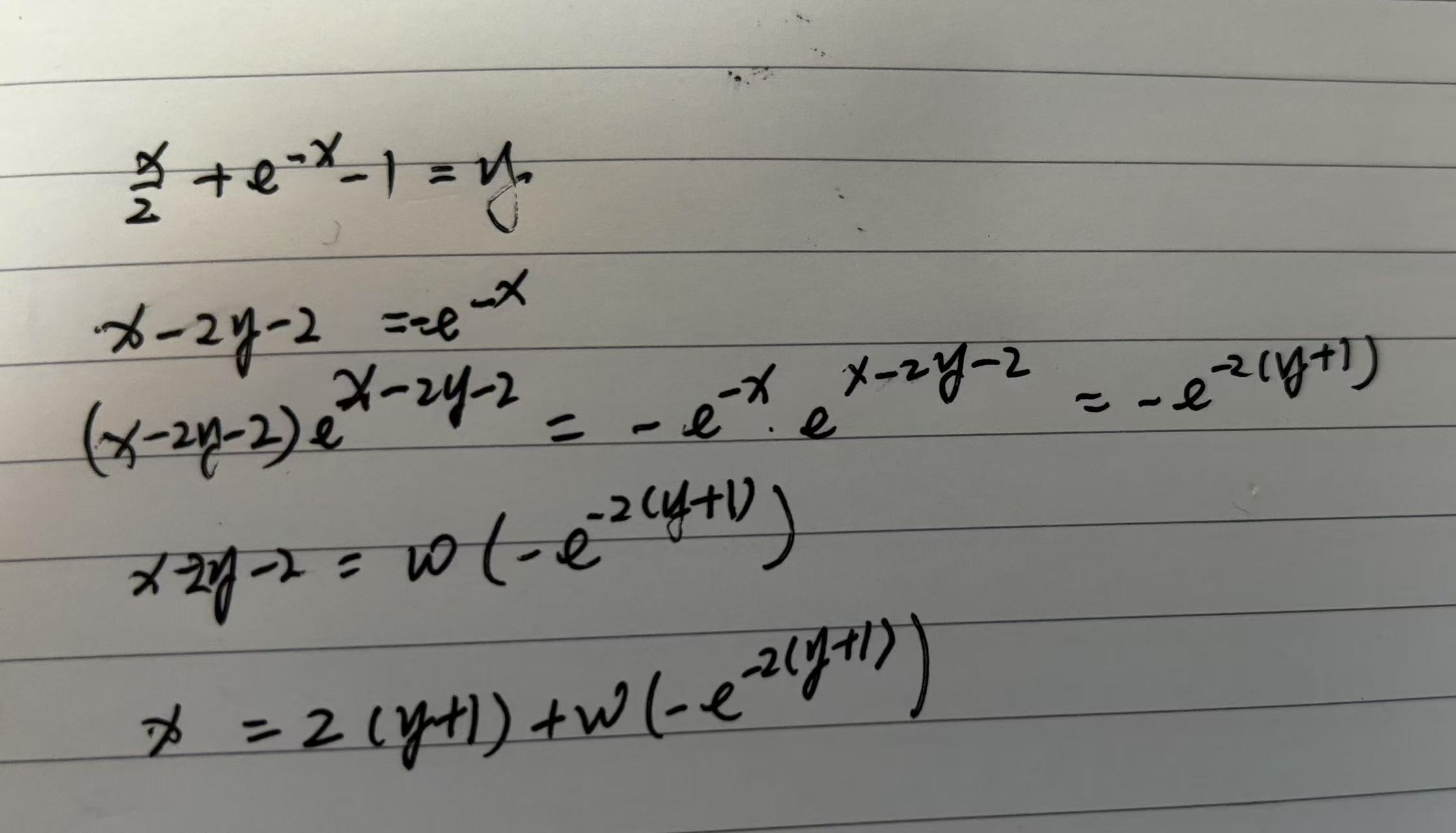
过去一年多,算是ChatGPT的深度用户,感觉也不错,一直花钱买VIP。但是对国产大模型用的不多。一方面最开始用户体验不好,一方面自己内心还是有点看不起国内的大模型。内心是不希望ChatGPT输的,所以反复尝试了多次,还是不行。
虽然GPT可能被我误导了,换个账号也许就没问题了?虽然这只个例,ChatGPT比国内大模型表现好的多了去了。但却破除了我心中的执念,以后有问题,也会在国内大模型试试了。
标签:
dreamable
个人推导错了 落了一个系数2.
这也是我们需要AI的原因啊